简介
二次筛法(Quadratic Seive)是由Pomerance于1981年提出的,直到1993年是世界上渐进最快的通用大整数因子分解方法,第一的位置后来被数域筛所取代,不过对于120位以下的整数,二次筛还是要比数域筛快一些。了解二次筛法前,需要先了解下费马分解法,因为二次筛法是来源于费马分解法的。
费马分解法
以分解大数
SPQS
多项式构造
在二次筛法中,我们先构造一个二次函数:
一般情况下
因子基
由上面的式子可得,我们可以看出
另外在选取 3.3 中进行介绍
线性组合
如上文所述,我们并不直接获取
假设在
我们将其记作
下面证明对于任意奇素数
对任意
example
下面我们举一例进行说明,这里取
首先选择因子基 1
2
3
4
5N = 15347
factor_base = [2]
for i in range(3, 100):
if isPrime(i) and kronecker(N, i) == 1:
factor_base.append(i)
选取
1 | sqtN = floor(N^0.5) |
利用筛法进行筛选:分别用集合中的元素出去因子基中的素数
1
2
3
4
5
6
7
8
9
10
11
12TT = [[i] for i in T]
for pri in factor_base:
for j in range(len(T)):
if TT[j][0] % pri == 0:
TT[j].append([pri, 0])
while TT[j][0] % pri == 0:
TT[j][0] //= pri
TT[j][-1][1] += 1
for i in range(len(T)):
if TT[i][0] == 1:
print(T[i], TT[i])
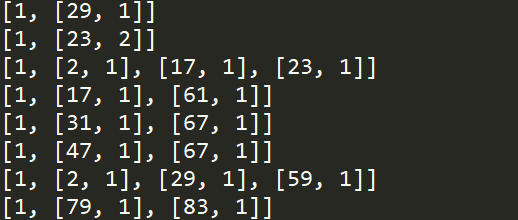
最终得到结果如下表:
| 1 | 29 | |
| 3 | 529 | |
| 4 | 782 | |
| 5 | 1037 | |
| 9 | 2077 | |
| 13 | 3149 | |
| 14 | 3422 | |
| 25 | 6557 |
由上面的表格我们不难看出很明显
此时
算法简述
- 选取因子基
,其中 满足: 是素数, - 计算出一系列的
- 通过筛法找到对于因子基
是光滑的所有 - 根据
构造指数矩阵 。 - 尝试找到矩阵
,满足 。 - 如果找不到矩阵
,回到第3步并扩大 的取值范围
MPQS
对于单个多项式的二次筛法(SPQS)而言,这种方法的主要困难在于,必须得到于因子基中素数差不多多的
相对而言,MPQS是对上述只用一个二次多项式的SPQS方法的一个改进,可以使用更多的二次多项式并行搜索(相当于非朴素并行化的改进),从而减小因子基
多项式构造
我们选择
若我们选择
假设我们选择
同时我们期望
- 关于为什么
? 当且仅当
时我们有, 此时对于任意
,才有 ,至此我们才能对因子基运用二次剩余进行筛选,不然同余方程右侧为 ,不容易进行筛选
- 为什么选取
为素数? 选取素数可以保证
较容易解出
- 为什么
要接近 选取 接近
可以保证极差较小,即 点值较小,减少基础运算的时间复杂度
选择系数的过程可以如下进行:
- 选择区间长度
。 - 选择接近于
的素数 。 - 求解
(求解这种离散对数问题用shanks、pollard's rho、Pohlig-Hellman算法)。 - 令
在 3.1 中,我们有如下等式: