这学期主要有六次作业,根据作业梳理了相关知识点,每个部分会首先介绍作业涉及的知识点,而后才是题目解析。
第一次作业
定义
- 强连通分量是指在有向图中,任意两个节点都互相可达的最大的子图
- 链入部分是指那些只有出边没有入边的节点。链出部分是指那些只有入边没有出边的节点。
- 卷须部分是指那些不属于任何强连通分量,但通过一条边与强连通分量连接
- 对于某对节点,若去除某个节点这对节点的距离增大,则称该节点为这对节点的关键节点。
题目1
给出下图的最大SCC,链入部分、链出部分
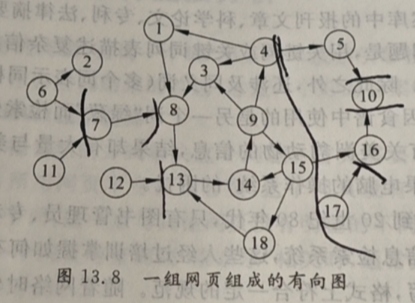
解析
对于上图
最大SCC:1、3、4、8、9、13、14、15、18
链入部分:6、7、11、12
链出部分:5、10、16
卷须:2、17
题目2
(a)请指出图13.8中一个可以添加或删除的边,使其可以增加最大强连通分量的规模。
(b)请指出图13.8中一个可以添加或删除的边,使其可以增加链入部分的规模。
(c)请指出图13.8中一个可以添加或删除的边,使其可以增加链出部分的规模。
解析
这里可以添加由8到7的边,添加后最大强连通分量新增节点7
这里可以添加由2到8的边,添加后链入部分新增节点2
这里可以添加由15到17的边,添加后链出部分新增节点17
题目3
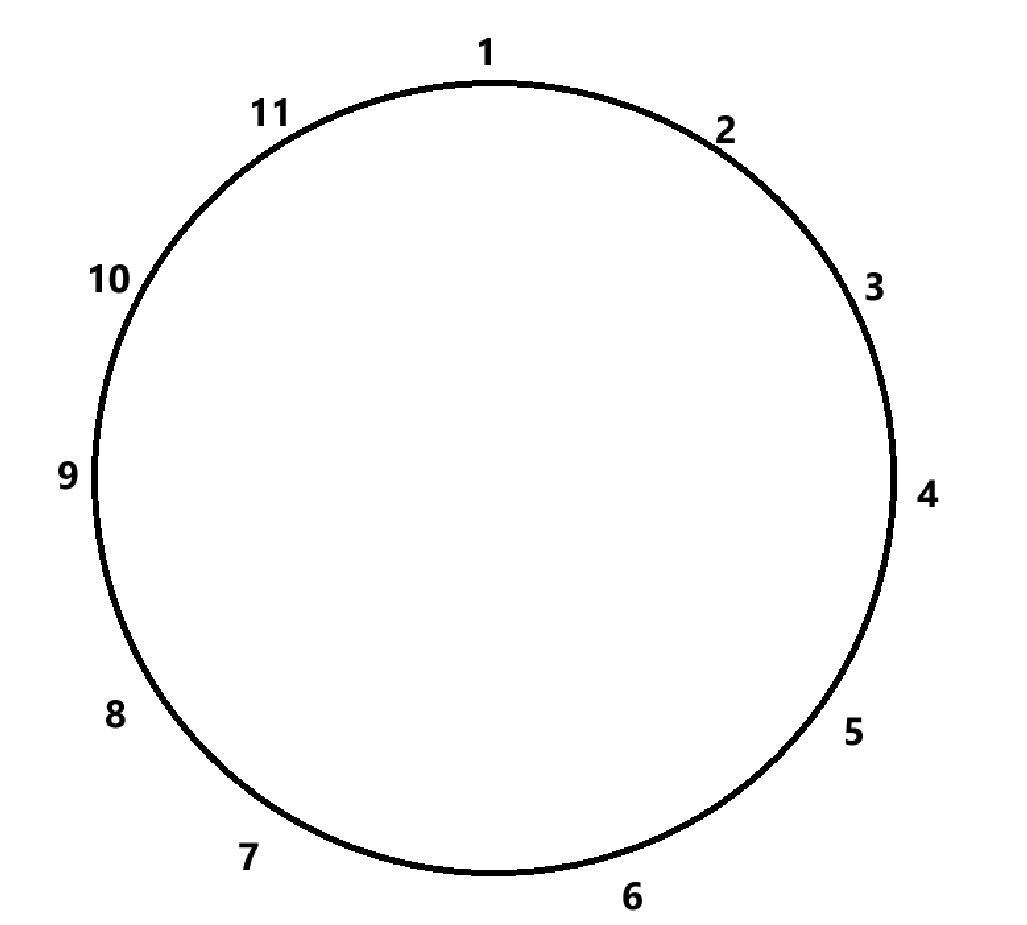
(1)请列举一个图例,使其满足以下条件:该图中每个节点均为至少一个节点对的关键节点。请就你的答案给出合理解释。
(2)请列举一个图例,使其满足以下条件:该图中每个节点均为至少两个节点对的关键节点。就你的答案给出解释。
(3)请列举一个图例,使其满足以下条件;该图中包含至少4个节点,并存在一个节点X,它是图中所有节点对的关键节点(不包括含X的节点组)。请给出合理解释。
解析
如图对于任意节点
,其必然为节点对 的关键节点,故同时满足第一问、第二问的情况
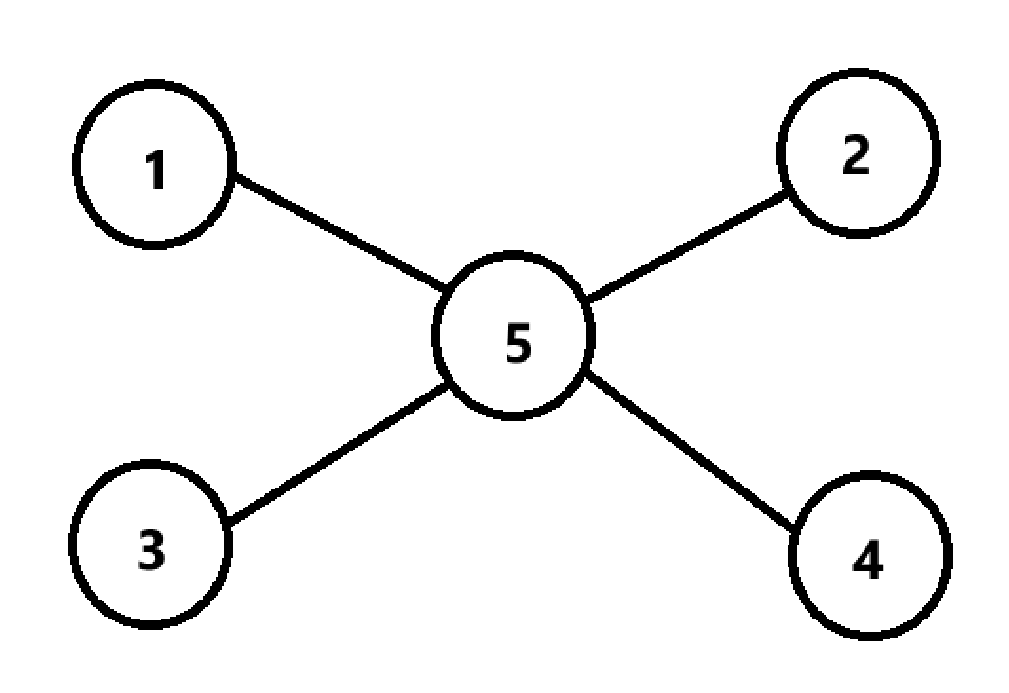
如上图节点5为除自身外所有节点的关键节点,满足第三问
题目4
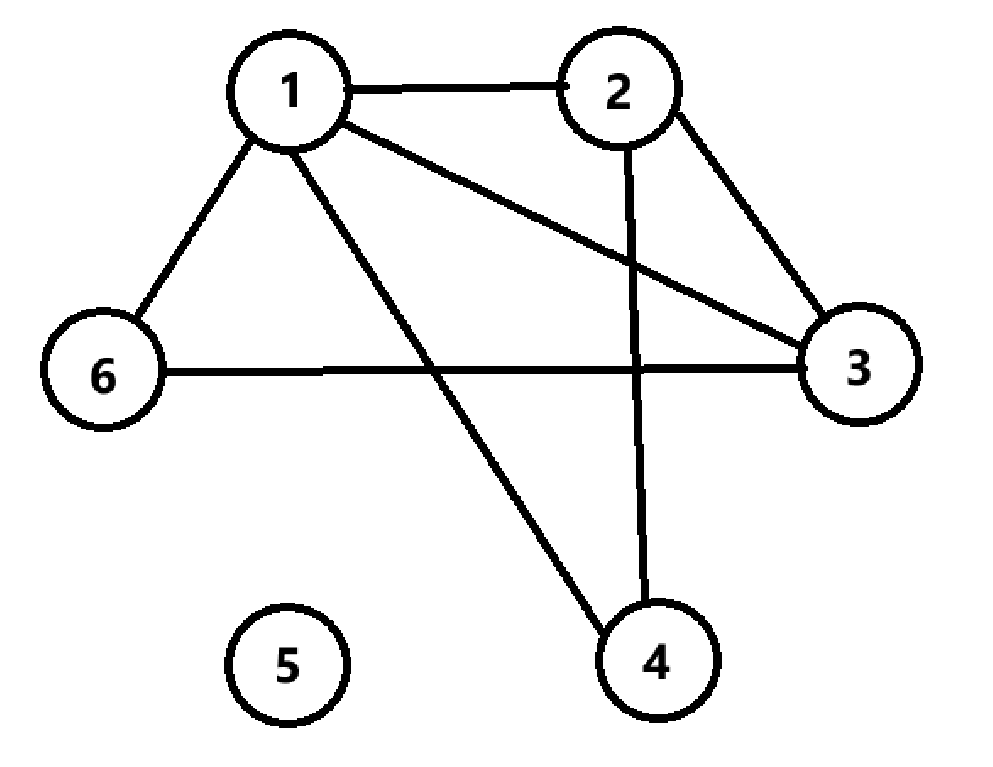
(1)给出上图的邻接矩阵和邻接表
邻接矩阵
1 | 1 2 3 4 5 6 |
邻接表
1 | 1 -> 2 -> 3 -> 4 -> 6 |
(2)然后交换图中标记为5和6的节点,看看邻接矩阵和邻接表的变化
事实上可以把5、6单看作编号,也就是现在将原来的5节点编号为6,6节点编号为5;那么改变事实上就是邻接矩阵、邻接表中5、6互换
(3)计算该图中节点的度分布
节点的度分布如下:
- 节点1的度:4
- 节点2的度:3
- 节点3的度:3
- 节点4的度:2
- 节点5的度:0
- 节点6的度:2
(4)并给出以3为顶点的宽度优先搜索树。
以节点3为顶点的宽度优先搜索树如下:
1 | 3 |
第二次作业
题目1
判断边BC是何种连接
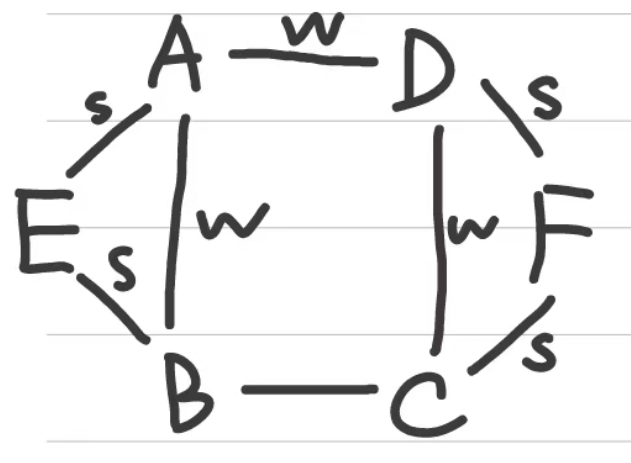
解析:使用反证法,如果边BC是强连接,那么根据强三元闭包假设,点C、点E之间必定存在连接,故可以推出矛盾。从而边BC为弱连接
题目2
下图中哪些节点违反强三元闭包,哪些满足。
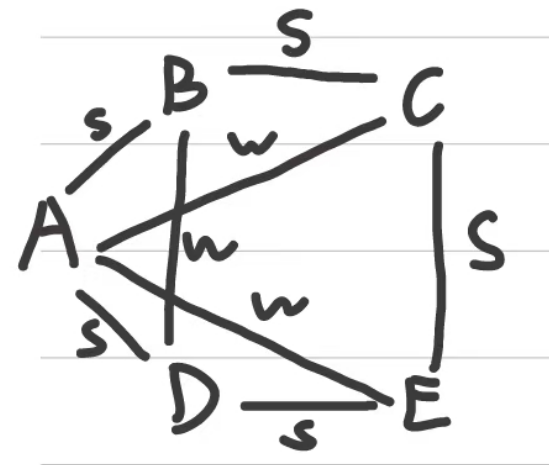
解析:
三元闭包: 若节点A与节点B和节点C均有强关系,而BC之间无任何关系,则称违反强三元闭包。
点B、点D 满足强三元闭包,这里由对称性,我们以其中一个节点B进行分析,节点D同理可以得到。由于点A、点C与点B均存在强关系,且点A、点C存在关系,故满足。
点C、点E 违反强三元闭包,这里由对称性,我们以其中一个节点C进行分析,节点E同理可以得到。由于点B、点E与点C均存在强关系,且点B、点E不存在关系,故两点违反强三元闭包。
聚集系数、邻里重叠度和介数
计算下图中节点A和B的聚集系数,边A-B的邻里重叠度和介数,并说明边A-B是否捷径?
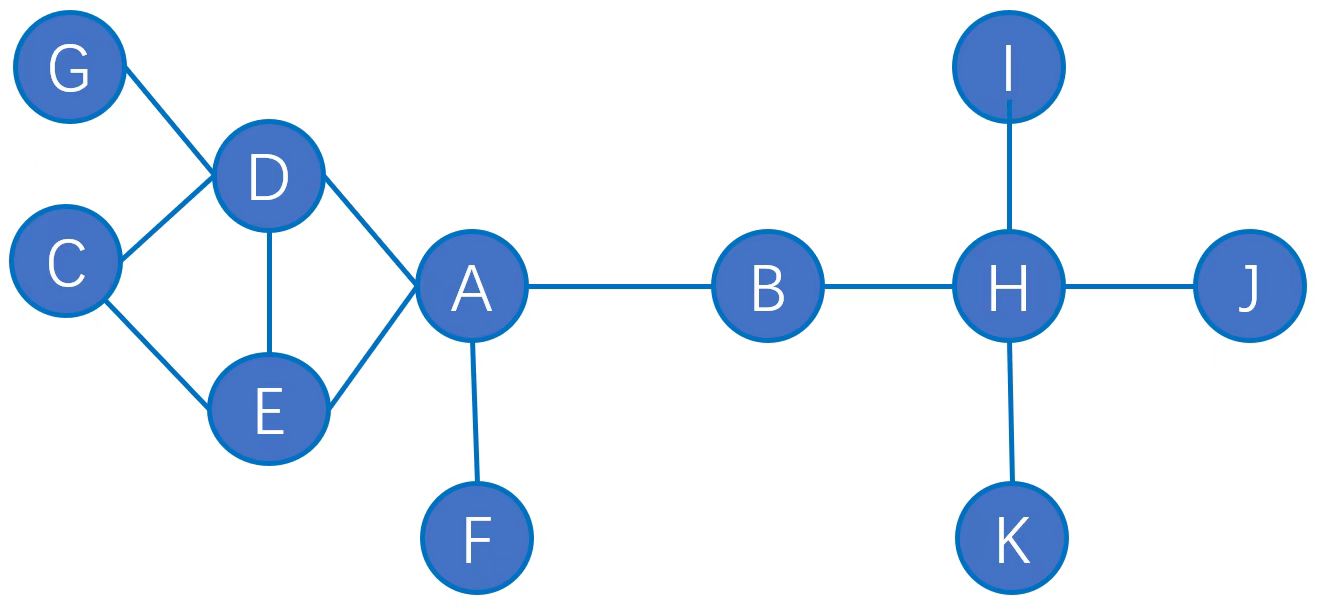
解析:
聚集系数 定义为某一节点的任意两个邻居彼此是邻居的概率。具体我们计算 A 的聚集系数,其任取两个邻居有6种可能,为邻居仅有1种可能,故聚集系数为1/6;B 任取两个邻居有1种可能,为邻居有0种可能,故聚集系数为0.
边A-B的 邻里重叠度 公式为
。具体我们计算 边A-B 的聚集系数,其与A、B均为邻居的节点数有0种可能,与A、B中至少一个为邻居的节点数有8种可能(A/B/D/E/F/H/I/K),故邻里重叠度为0 边介数定义为网络中所有 最短路径中经过该边的路径的数目 占 最短路径总数 的比例。具体我们计算 边AB 的聚集系数,最短路径中经过该边的路径的数目有
种,最短路径总数有 种,故介数为 若 边A-B 的两端点没有共同朋友,那么称 边A-B 为 捷径。对于上图A、B之间不存在共同邻居节点,故边AB为捷径。
题目3
在 CXPST 中,Max Schuchard对边的介数定义进行了修改,将其定义为穿越节点块间 BGPpath 经过该边的数量,他这样修改的原因是什么?
- 风险评估:修改边的介数定义,使其基于BGP路径的数量,可以更精确地识别那些对于网络通信最为关键的边,从而更好地评估风险。
- 网络的实际流量:传统的介数定义是基于所有可能的最短路径,而不考虑实际流量。在互联网路由中,BGP路径代表了实际的数据流量。因此,基于BGP路径的介数更能反映网络的实际使用情况。
- 网络的实际拓扑:互联网的拓扑结构非常复杂,并且不断变化。BGP路径反映了网络的实际路由决策,因此,使用BGP路径来定义边的介数能够更准确地反映网络的实际拓扑结构和路由策略。
- 关注自治系统间的连接:BGP主要用于不同自治系统(AS)之间的路由决策。修改介数的定义可以帮助研究者在自治系统级别上理解网络结构,这对于理解互联网的大规模结构和行为至关重要。
- 提高预测精度:通过考虑实际的路由路径,可以提高对网络行为和潜在故障点的预测精度。例如,在预测网络中的故障传播或设计网络加固策略时,基于BGP路径的介数可能更有指导意义。
- 适应特定网络特性:不同的网络有不同的特性。在互联网这样的复杂网络中,传统的介数定义可能不完全适用。Max Schuchard的修改可能是为了使介数的定义更加适应互联网的特性。
中心性
计算下图节点B的度中心性,介数中心性和接近中心性。
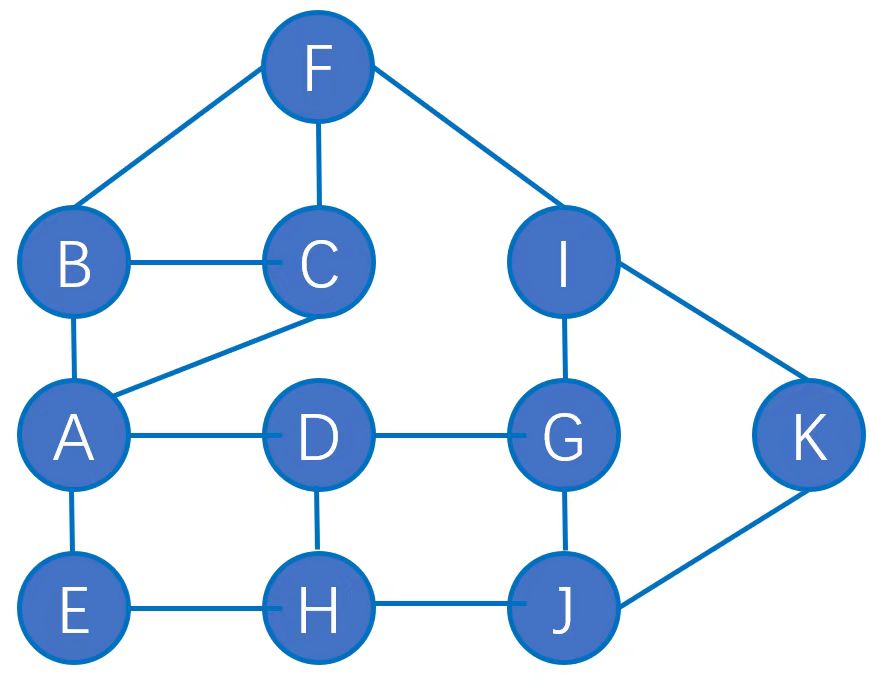
解析:
度中心性(Degree Centrality) 是在网络分析中刻画节点中心性(Centrality)的最直接度量指标。一个节点的节点度越大就意味着该节点的度中心性越高,该节点在网络中就越重要。
节点 度中心性 计算公式如下:
其中
表示现有的与节点 相连的边的数量; 表示节点 与其他节点都相连的边的数量 具体点B的度中心性为
节点介数是指一个网络里通过节点的最短路径条数
某个节点的 介数中心性(Betweenness Centrality) 的计算公式如下:
其中
表示经过节点 ,且为最短路径的路径数量; 表示连接 和 的最短路径的数量 具体点B的介数中心性为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import networkx as nx
# 创建一个空的图
G = nx.Graph()
# 添加节点和边以匹配图片中的图
nodes = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K']
edges = [
('A', 'B'), ('A', 'C'), ('A', 'D'), ('A', 'E'),
('B', 'C'), ('B', 'F'),
('C', 'F'),
('D', 'G'), ('D', 'H'),
('E', 'H'),
('F', 'I'),
('G', 'I'), ('G', 'J'),
('H', 'J'),
('I', 'K'), ('J', 'K')
]
# 将节点和边添加到图中
G.add_nodes_from(nodes)
G.add_edges_from(edges)
# 计算介数中心性
betweenness_centrality = nx.betweenness_centrality(G, normalized = False)
# 输出节点 B 的介数中心性
print(f"B's Betweenness Centrality: {betweenness_centrality['B']}")接近中心性(Closeness Centrality) 用于衡量节点重要性
某个节点的 接近中心性 为:
其中
表示节点 到其余各点的平均距离,平均距离的倒数就是接近中心度 这里计算B的 接近中心性:
PageRank
马尔科夫链
俄国数学家 Andrey Andreyevich Markov 研究并提出一个用数学方法就能解释自然变化的一般规律模型,被命名为马尔科夫链(Markov Chain)。马尔科夫链为状态空间中经过从一个状态到另一个状态的转换的 随机过程,该过程要求具备“无记忆性 ”,即下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之关。
通过马尔科夫链的模型转换,我们可以将事件的状态转换成概率矩阵 (又称状态分布矩阵 ),如下例:
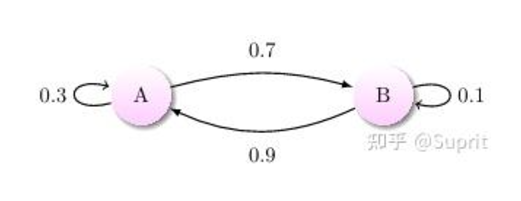
假设初始状态在 A,如果我们求 2 次运动后状态还在 A 的概率是多少?
这里我们可以求出
一般地我们可以引入转移概率矩阵 ,可以非常直观的描述所有的概率。
针对上面例子,假设我们初始状态为
intro
在互联网的早期历史中,PageRank 算法 被引入作为一种评估网页重要性的方法。简而言之,PageRank 是一个定义在整个网页集合上的函数,为每个网页分配一个正实数,代表该网页的重要性。这些数值组成一个向量,其中较高的 PageRank 值意味着该网页在重要性上的优势,因此在搜索结果中可能会被优先显示。
可以将整个互联网视为一个巨大的有向图,其中每个网页是一个节点,而超链接则是从一个页面指向另一个页面的有向边。基于这个视角,我们可以构建一个随机游走模型,也就是一阶马尔可夫链。在这个模型中,我们假设一个虚拟的网页浏览者会随机地、按照等概率地跟随一个页面上的任何一个超链接到另一个页面,并持续这种随机跳转。在长时间内,这种随机跳转的行为会形成一个稳定的模式,即马尔可夫链的平稳分布。每个网页的 PageRank 值,实际上就是在这个平稳分布中的概率。
直观上,一个网页,如果指向该网页的超链接越多,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。一个网页,如果指向该网页的PageRank值越高,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。PageRank值依赖于网络的拓扑结构,一旦网络的拓扑(连接关系)确定,PageRank值就确定。
随机游走模型
给定一个含有
注意转移矩阵具有性质:
在有向图上的随机游走形成马尔可夫链。也就是说,随机游走者每经一个单位时间转移一个状态,如果当前时刻在第
PageRank 的基本定义
给定一个包含
显然有
PageRank的基本定义是理想化的情况,在这种情况下,PageRank存在,而且可以通过不断迭代求得PageRank值。
PageRank 的一般定义
PageRank 一般定义的想法是在基本定义的基础上导入平滑项。
给定一个含有
可以由
给定一个含有
一般 PageRank
的定义意味着互联网浏览者,按照以下方法在网上随机游走:任意一个网页上,浏览者或者以概率
PageRank 的计算
PageRank 的定义是构造性的,即定义本身就给出了算法。本节列出 PageRank 的 计算方法包括法代算法、幕法、代数算法。常用的方法是事法。
迭代算法
给定一个含有
输入:含有
个结点的有向图,转移矩阵 , 阻尼因子 , 初始向量 输出:有向图的 PageRank 向量
- 令
- 计算
- 如果
与 充分接近,令 停止迭代。 - 否则
,重新执行上面条件
代数算法
代数算法通过一般转移矩阵的逆矩阵计算求有向图的一般 PageRank。
按照一般 PageRank 的定义式
题目4
设初始网页排名值为1/8,请求出5轮后各节点PR值是多少,请给出过程。
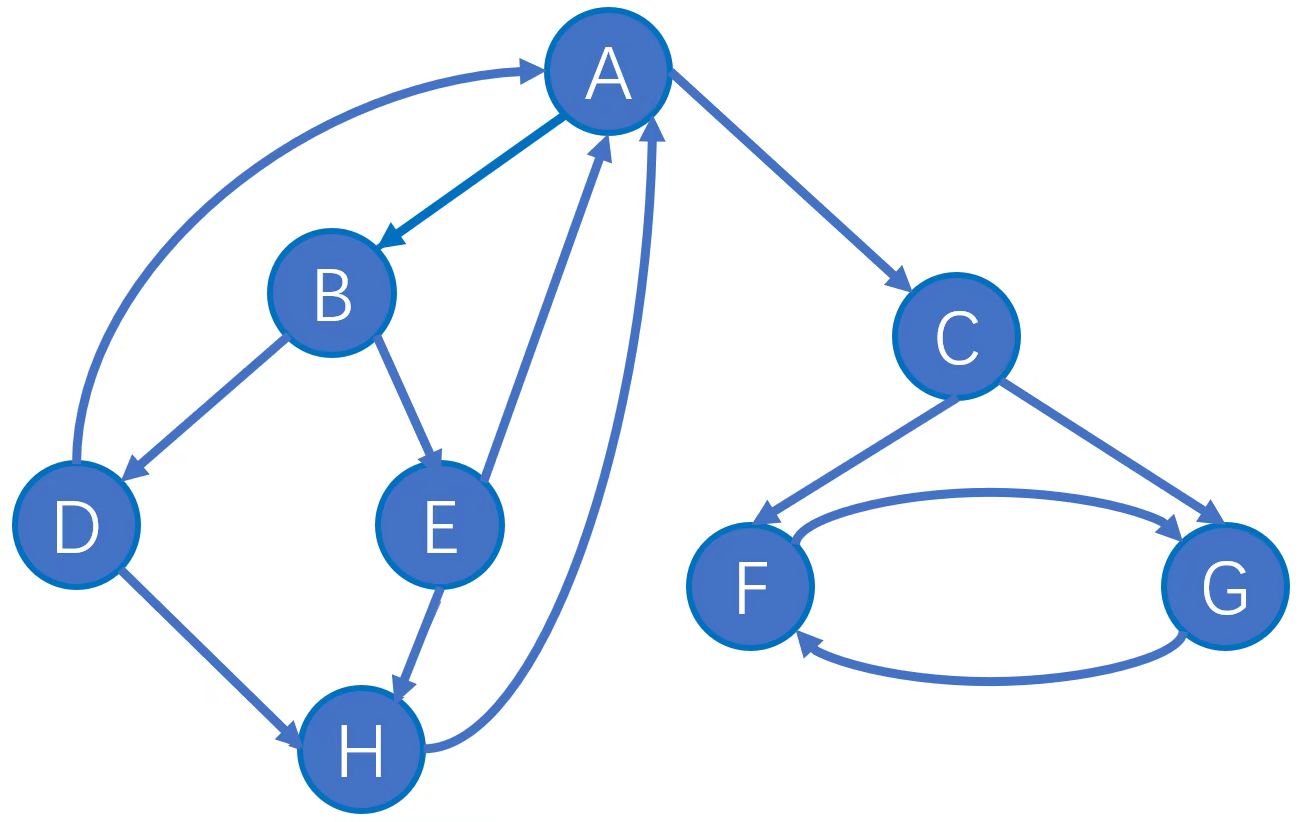
1 | v = matrix([[1/8] for i in range(8)]) |
第三次作业
题目1
谢林模型表达的是人们对同质性的需求与形成社会隔离之间的关系。在书中,模型假设一个人潜在可能有8个邻居,如果和自己"同类的邻居"数
- 更低的搬家阈值:个体对于
同类邻居的需求降低,因此他们更少搬家。即使周围大多数邻居不是同类,只要至少有1个同类邻居,个体就会选择留下。 - 更少的区隔:由于个体更容易满足留下条件,因此整个社区的区隔现象会减少。社区可能会更加混合,因为个体不会因为只有少数“同类”邻居就搬家。
- 更慢的区隔形成:即使在某些区域开始出现同质性群体,由于较低的搬家阈值,这种趋势会发展得更慢。个体不会因为只有少数不同类的邻居就轻易搬家,因此同质性群体的形成速度会减慢。
- 更稳定的社区结构:在
的情况下,社区结构可能会更加稳定,因为个体搬家的频率降低,社区的组成变化会更小。 - 可能的局部聚集:尽管整体区隔减少,但在某些局部区域,如果“同类”个体偶然聚集,可能会形成小规模的同质性群体,但这种聚集不会像
时那样迅速扩展到整个社区。
总的来说,当
题目2
假设在某一时刻,有以下社会归属网络。随着时间推移,根据三元闭包、社团闭包和会员闭包的原则,将出现新的关联。假设三元闭包门槛值为3,会员闭包门槛值为2,社团闭包门槛值为2。试给出该网络的演化过程,直至不再变化。
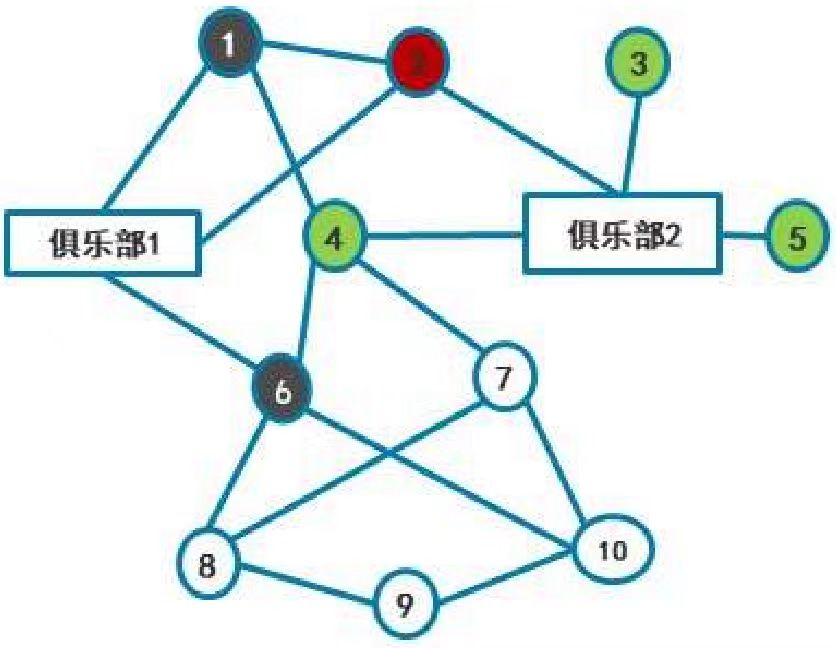
解析:
为了操作的方便,我们把三个闭包原理简化为三个门槛假设:
- 三元闭包:如果两个不相识的人有了
个或更多共同朋友,则他们下一时点前会成为朋友 - 社团闭包:如果两个不相识的人参加了
个或更多相同的俱乐部,则他们在下一时点前会成为朋友 - 会员闭包:如果某人有
个或更多朋友参加了某个俱乐部,则他在下一时点前参加该俱乐部
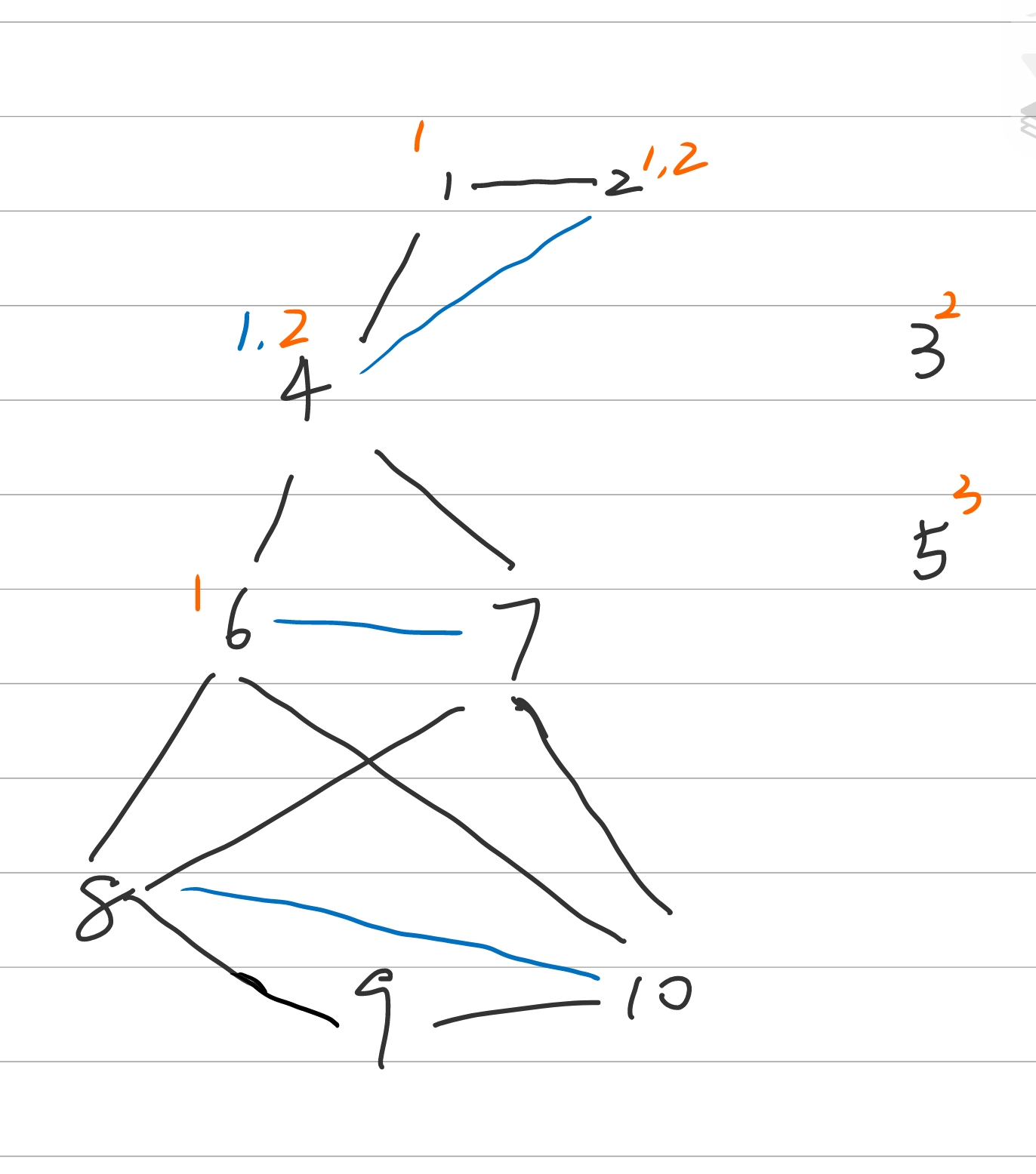
分析过程如上图所示
第一轮:
根据三元闭包,节点6、7成为朋友;节点8、10成为朋友
根据会员闭包,节点4参加俱乐部1
第二轮:
根据社团闭包,节点2、4成为朋友
题目3
在下图中,假设你有形成两条边的资源,如何添加能最大限度降低同质性,请说明其原因。假设你有改变一个节点的资源,改变哪一个能最大限度降低同质性,请说明其原因。
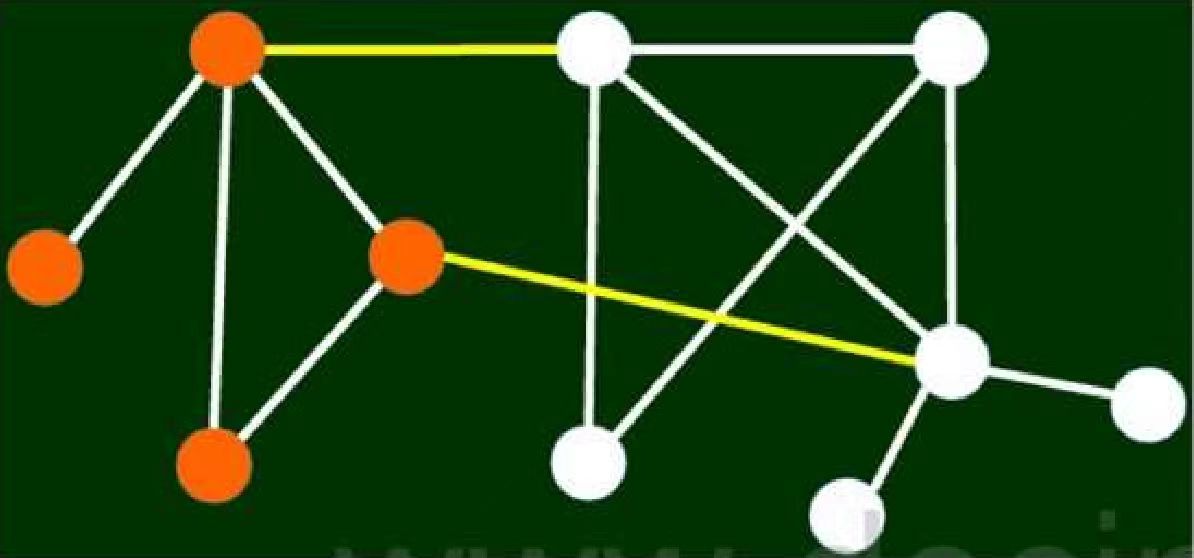
删除图中黄色的两条边,可以看到原图变成两个新的子图,其中两个子图社区中所有节点均同质
删除第一行的第二个白色节点,此时生成两个社区,且两个社区中所有节点均同质,并且两个社区仅通过一条捷径连通
第四次作业
囚徒困境
假设有两个犯罪嫌疑人被警察分别关押,并且不能相互沟通。警察没有足够的证据来起诉他们,于是分别向他们提出了一个交易:
- 如果一个嫌疑人(我们称他为A)向警察坦白(背叛对方),而另一个嫌疑人(我们称他为B)保持沉默,那么A将被释放,而B将被判最重的刑罚。
- 如果B向警察坦白,而A保持沉默,那么B将被释放,而A将被判最重的刑罚。
- 如果A和B都向警察坦白(互相背叛),那么他们都将被判刑,但刑罚会比单独背叛对方轻一些。
- 如果A和B都保持沉默(互相合作),那么他们都将因为证据不足而被判最轻的刑罚。
在这个情况下,每个嫌疑人都面临一个选择:坦白或保持沉默。从个体理性的角度出发,无论对方如何选择,每个嫌疑人选择坦白都是最优策略,因为这样可以确保自己不会受到最重的刑罚。然而,如果两人都选择坦白,结果就是他们都受到较重的刑罚,这并不是社会最优的结果。如果两人都能合作保持沉默,他们将获得更好的整体结果(最轻的刑罚)。但因为缺乏信任和沟通,以及追求个人最优利益的动机,最终往往导致双方都选择坦白,陷入了"困境"。
题目1
在二人博弈的纳什均衡中,每个参与人都选择了一个最优策略,所以两个参与人的策略是社会最优。这个陈述是否正确?
假设你认为是正确的,请给出简要说明(13句话)来解释为什么正确。假设你认为不正确的,请举出一个第6章讨论过的博奔例子来说明它是错误的(你不需要写出有关博弈的具体细节,仅提供你认为能清楚表达你的意思的内容),附加上简要解释(13句话)。
解析
在二人博弈的纳什均衡中,每个参与人选择的最优策略仅是针对对方策略的最优响应,并不意味着这种策略组合是社会最优。一个经典的例子是囚徒困境,其中两个理性的个体各自追求自身利益最大化的策略,导致了一个对双方都不利的结果,而不是社会最优解。这说明纳什均衡并不总是导致社会最优,因为它没有考虑到合作可能带来的更大收益。
Nash 均衡
个人理解,对于二元组
题目2
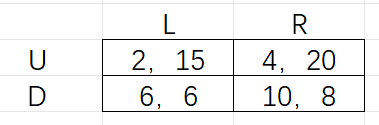
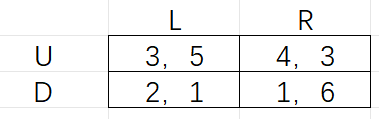
在下面每个收益矩阵,行都代表这参与人A的策略选择,列代参有人B的策略。每个单元格的第一个数代表者参与人A的收益,第二个数代表着参与人B的收益。 (a)对图1描述的收益矩阵,找出该博弈中的所有的纯(非随机性)策略的纳什均衡。 (b)对图2描述的收益矩阵,找出该博弈中的所有的纯(非随机性)策略的纳什均衡。 (c)在图3的收益矩阵中,找出博弈中所有的纳什均衡。

解析
图一 Nash均衡 为
图二 Nash均衡 为
图三 Nash均衡 为
题目3
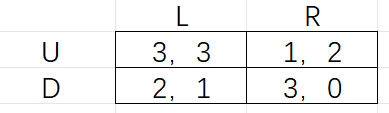
图4的收益矩阵中,行代表参与人A的策略选择,列代表参与人B的策略选择,每个单元格的第一个数代表参与人A的收益,第二个数代表参与人B的收益。
(a)找出该博弈的所有纯策略纳什均衡
(b)上面的收益矩阵中,策略组(U,L)反应的参与人会的收益是3.你可以用类似方法,用一个非负数改变这组策略代表的参与人A的收益,并使其结果中没有纳什均吗?加以简要解释(1~3句话)。(注意:本题中,你只能改变参与人在策略组(U,L)中的收益情况,特别注意,剩下的博弈结构是没有改变的,即参与人,参与人策略,从策略中的收益都是没有改变的以及参与人B从策略组(U,L)中获得的收益不会改变,只有参与人A在策略组(U,L)的收益改变。)
(c)现在,先返回(a)部分的初始收益矩阵中,并仅对参与人B进行类似的问题寻找。我们先返回到初始收益矩阵,参与人A和B在策略组
解析
图4 中 Nash均衡为
不可能。无论
的策略是什么, 的最优策略均为 ,故在 选择策略 时, 无论选择 或者 均为 Nash 均衡。 这里只需要设置其值为小于2的任意数即可
题目4
两家完全一样的公司,让我们称们为公司1和公司2,要同时且独立地决定是否要进入一个新的市场。并且如果进入,要生产什么产品(有A或者B可选)。如果两家公司都进入,且都生产A,他们各自要损失1千万美元;如果都进入,且都生产B,它们则分别会获得500万美元利润;如果两家公司都进入,但一家生产A,另一家生产B,则分别赚取1千万美元;如果不进入市场,则利润为0;最后,如果一个进入,另一个不进入,生产A就赚1.5千万,生产B的话就赚3千万。
你是公司1的经理,要为你的公司选择一个策略。
(a)将这种情形建模成一个博弈,包括两个参与者(1和2)和三种策略(生产A,生产B,不进入)。
(b)你的一个员工说应该进入市场(尽管他不肯定该生产什么产品),因为无论公司2怎么做,进入市场并生产B总比不进入强,试评估这种观点。
(c)另一个员工同意刚才那位的观点,并且说由于策略A会导致损失(若另一家公司也生产A),你应该进入且生产B。如果两家公司都如此推理,都进入市场且生产B,这个博弈形成了纳什均衡吗,请解释。
(d)找到这个博弈中的所有纯策略纳什均衡
(e)你公司的另一个员工建议合并这两家公司,协作决定最大化利润的策略。不考虑有关法规是否介许这种合并,你认为这是一个好主意吗?请解释。
解析
- 我们构建一个
的列表,其中 分别表示公司 1 生产 以及不生产; 分别表示公司 2 生产 以及不生产。列表中第一项表示公司1的收益,第二项表示公司2的收益。
- 正确。无论公司2策略选择如何,生成
总能产生收益。
对于 (c)(d) 我们同时回答,我们对所有最优策略产生的收益标注为
可以看到 Nash 均衡策略为
- 合理。两家公司合并后,可以进入市场生产
,平均每家公司可以分到 收益,高于 Nash 均衡收益。
题目5
假如田忌不知道齐威王的赛马策略,请你代替孙膑帮田忌设计马的出场次序。要求:三元素、假设(给出依据)
解析
不失一般性,我们给齐威王三匹马赋值为
下面我们仅用赋值顺序构成的三元组代表马出场的顺序。假设齐威王分配较为随机,分配6种策略(
1 | from itertools import permutations |
最后得到
| 策略 | |
|---|---|
故可以随机排列都不影响获胜概率。
题目6
在齐王每个等级的马都优于田忌同等级的马,且田忌高一等级的马优于齐王低一等级的马的条件下,对齐王来说,3局2胜和5局3胜哪个更有利?
解析
修改代码如下
1 | from itertools import permutations |

得到齐威王三局两胜的胜率为
第五次作业
题目1
有
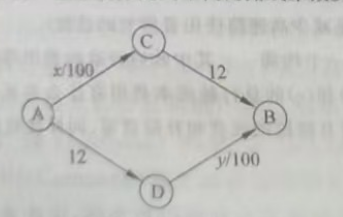
(a)试求
根据路径的对称性,我们仅讨论当
由于
此时对于选择路径 A-C-B 的司机,保持原路线的行驶时间为
此时
对于任意司机,由于
初始的总行驶时间为
(c)假定路况经过改善,边BC 和 边AD 的行驶时间均减至
假设 CD 仍然存在,那么当且仅当
假使政府关闭从 CD 的道路。由于
此时对于选择路径 A-C-B 的司机,保持原路线的行驶时间为
题目2
两条路将A城和B城连接到一起。80个人从A城出发向B城行驶。路线1从A城开始先经过一条高速公路:这条高速公路不论有多少辆车,行驶时间均为1小时,然后连接到一条能到达B城的普通道路。这条通在B城的普通道路行驶时间为10加上行驶在该道路上的车辆数,以分钟计算。路线2从A城出发纵一条普通道路开始,行驶时间为10加上行驶在该道路上的车辆数,同样以分钟计算。该普通道路连接一条直接通往B城的高速路,其行驶时间与行驶车辆无关,为1小时。
(a)画出上述描述的网格、在每边标出所需的行驶时间,设x为采用路线1的人数,因为所有路线均为单向,此网络为有向图。
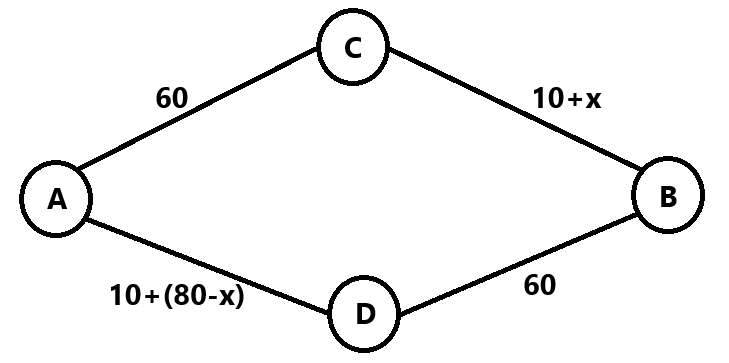
(b)所有车辆同时选择路线,找出
可以得到当且仅当
(c)政府修建了一条双向的新路,这条新路增加了两条路线,一条是从a出发进入普通路线,(在路线2上)、再进入新路和通向b城的普通路上(在路线上)。另一条路线由a出发进入高速路(在路线1上),然后进入新路以及通往b城的高速路(在路线二上)。新路非常短,其行驶时间可以忽略不计,找出这个新的纳什均衡。
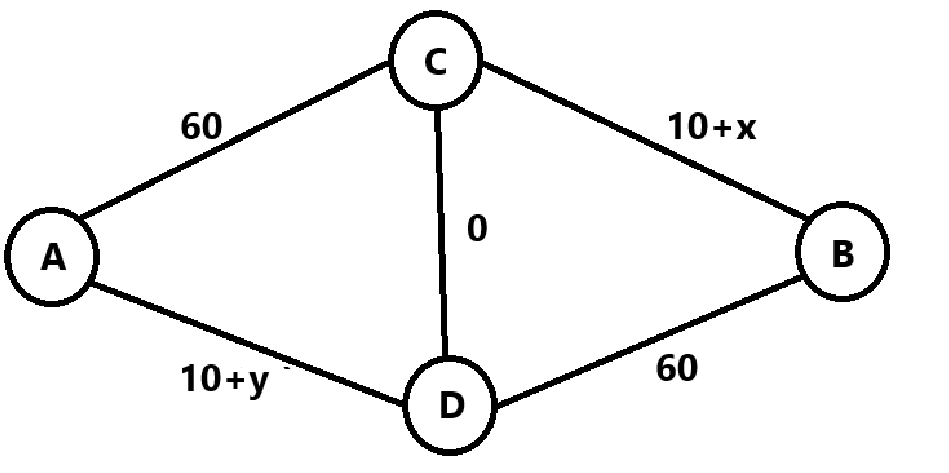
这里可以直接将 CD看作一个节点 C',对于A 到 C',当
新路出现前总行驶时间为
(e)假如你可以为车辆分配路线,实际上可以使总行驶时间比新路建设前少。也就是说通过路线分配可以减少所有车辆的总行驶时间(低于(b)中纳什均衡对应的值),有很多分配法可以达到这个目标。找到其中的一个,并解释你的分配方法是如何减少行驶时间的。
下面给出总行驶时间最少的一种方案:
由于新路是双向的,且边权为0,我们可以将点 C 和点 D看作一个整体
C'。故所有司机必须先到达 C' 后到达 B。这里先假设走 AD 的人数为
同理对于 C' 至 B,最小行驶时间为
可以得到总的行驶时间为
第六次作业
关于一些定义
最近耦合网络:是一种规则网络模型,其中每个节点仅与其最近的一定数量的邻居节点相连。
全局耦合网络:是一种规则网络模型,其中网络中的 任意两个节点之间都有边直接相连。这种网络模型也被称为完全图。
星型网络:是一种网络拓扑结构,其中有一个中心节点连接到所有其他节点,而其他节点之间不直接相连。
聚集系数:是网络科学中用来衡量网络中节点的邻居之间相互连接程度的指标,其值为图中连接的边除所有可能连接的边的数量。
题目1
计算
边数:
网络直径:
平均路径长度:我们根据定义具体有
全局耦合网络
对于一个具有
边数:
网络直径:全局耦合网络的直径
平均路径长度:全局耦合网络的平均路径长度
聚集系数:全局耦合网络的聚集系数
星型网络
对于一个具有
边数:
网络直径:星型网络的直径
平均路径长度:星型网络的平均路径长度
聚集系数:星型网络的聚集系数
比较分析
- 边数:全局耦合网络的边数最多,星型网络的边数最少,最近邻耦合网络的边数介于两者之间。
- 网络直径:全局耦合网络的直径最小,星型网络的直径次之,最近邻耦合网络的直径最大。
- 平均路径长度:全局耦合网络的平均路径长度最小,星型网络的平均路径长度次之,最近邻耦合网络的平均路径长度最大。
- 聚集系数:全局耦合网络的聚集系数最高,最近邻耦合网络的聚集系数次之,星型网络的聚集系数最低。
题目2
假如ER网络的节点数为
期望连接数
平均度
注意这里笔者开始直接使用
,但事实上 表示每个节点平均分到的边的数量,而一条边由两个节点共享,所以应该有
平均路径长度
度分布
代入有
判断是否存在巨大连通分量
在ER网络中,当平均度